试题四(共 15 分)阅读以下说明和代码,填补代码中的空缺,将解答填入答题纸的对应栏内。【说明】 图是很多领域中的数据模型,遍历是图的一种基本运算。从图中某顶点 v出发进行广度优先遍历的过程是:①访问顶点 v;②访问 V 的所有未被访问的邻接顶点 W1 ,W2 ,..,Wk;③依次从这些邻接顶点 W1 ,W2 ,..,Wk 出发,访问其所有未被访问的邻接顶 点;依此类推,直到图中所有访问过的顶点的邻接顶点都得到访问。显然,上述过程可以访问到从顶点 V 出发且有路径可达的所有顶点。对于 从 v 出发不可达的顶点 u,可从顶点 u 出发再次重复以上过程,直到图中所有顶 点都被访问到。例如,对于图 4-1 所示的有向图 G,从 a 出发进行广度优先遍历,访问顶点 的一种顺序为 a、b、c、e、f、d。图 4-1设图 G 采用数组表示法(即用邻接矩阵 arcs 存储),元素 arcs[i][ j]定义如下: 图 4-1 的邻接矩阵如图 4-2 所示,顶点 a~f 对应的编号依次为 0~5.因此,访问顶点 a 的邻接顶点的顺序为 b,c,e。函数 BFSTraverse(Graph G)利用队列实现图 G 的广度优先遍历。相关的符号和类型定义如下:#define MaxN:50 /*图中最多顶点数*/ typedef int AdjMatrix[MaxN][MaxN];typedef struct{int vexnum,edgenum;/*图中实际顶点数和边(弧)数*/ AdjMatrix arcs; /*邻接矩阵*/)Graph;typedef int QElemType; enum {ERROR=0;OK=l};代码中用到的队列运算的函数原型如表 4-1 所述,队列类型名为 QUEUE。表 4-1 实现队列运算的函数原型及说明 【代码】int BFSTraverse(Graph G){//图 G 进行广度优先遍历,图采用邻接矩阵存储unsigned char*visited; //visited[]用于存储图 G 中各顶点的访问标 志,0 表示未访问int v,w;u; QUEUEQ Q;∥申请存储顶点访问标志的空间,成功时将所申请空间初始化为 0 visited=(char*)calloc(G.vexnum, sizeof(char));If( (1) ) retum ERROR; (2) ; //初始化 Q 为空队列 for( v=0; v } free(visited);return OK;)//BFSTraverse从下列的 2 道试题(试题五至试题六)中任选 1 道解答。请在答题纸上的 指定位置处将所选择试题的题号框涂黑。若多涂或者未涂题号框,则对题号最小 的一道试题进行评分。
试题四(共 15 分)阅读以下说明和代码,填补代码中的空缺,将解答填入答题纸的对应栏内。【说明】 图是很多领域中的数据模型,遍历是图的一种基本运算。从图中某顶点 v出发进行广度优先遍历的过程是:①访问顶点 v;②访问 V 的所有未被访问的邻接顶点 W1 ,W2 ,..,Wk;③依次从这些邻接顶点 W1 ,W2 ,..,Wk 出发,访问其所有未被访问的邻接顶 点;依此类推,直到图中所有访问过的顶点的邻接顶点都得到访问。显然,上述过程可以访问到从顶点 V 出发且有路径可达的所有顶点。对于 从 v 出发不可达的顶点 u,可从顶点 u 出发再次重复以上过程,直到图中所有顶 点都被访问到。例如,对于图 4-1 所示的有向图 G,从 a 出发进行广度优先遍历,访问顶点 的一种顺序为 a、b、c、e、f、d。图 4-1
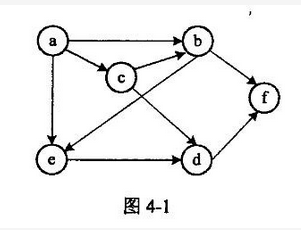
设图 G 采用数组表示法(即用邻接矩阵 arcs 存储),元素 arcs[i][ j]定义如下:

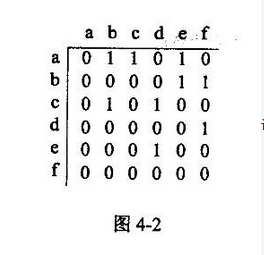
图 4-1 的邻接矩阵如图 4-2 所示,顶点 a~f 对应的编号依次为 0~5.因此,访问顶点 a 的邻接顶点的顺序为 b,c,e。函数 BFSTraverse(Graph G)利用队列实现图 G 的广度优先遍历。相关的符号和类型定义如下:#define MaxN:50 /*图中最多顶点数*/ typedef int AdjMatrix[MaxN][MaxN];typedef struct{int vexnum,edgenum;/*图中实际顶点数和边(弧)数*/ AdjMatrix arcs; /*邻接矩阵*/)Graph;typedef int QElemType; enum {ERROR=0;OK=l};代码中用到的队列运算的函数原型如表 4-1 所述,队列类型名为 QUEUE。
表 4-1 实现队列运算的函数原型及说明

【代码】int BFSTraverse(Graph G){//图 G 进行广度优先遍历,图采用邻接矩阵存储unsigned char*visited; //visited[]用于存储图 G 中各顶点的访问标 志,0 表示未访问int v,w;u;
QUEUEQ Q;∥申请存储顶点访问标志的空间,成功时将所申请空间初始化为 0 visited=(char*)calloc(G.vexnum, sizeof(char));If( (1) ) retum ERROR; (2) ; //初始化 Q 为空队列 for( v=0; v
设图 G 采用数组表示法(即用邻接矩阵 arcs 存储),元素 arcs[i][ j]定义如下:
图 4-1 的邻接矩阵如图 4-2 所示,顶点 a~f 对应的编号依次为 0~5.因此,访问顶点 a 的邻接顶点的顺序为 b,c,e。函数 BFSTraverse(Graph G)利用队列实现图 G 的广度优先遍历。相关的符号和类型定义如下:#define MaxN:50 /*图中最多顶点数*/ typedef int AdjMatrix[MaxN][MaxN];typedef struct{int vexnum,edgenum;/*图中实际顶点数和边(弧)数*/ AdjMatrix arcs; /*邻接矩阵*/)Graph;typedef int QElemType; enum {ERROR=0;OK=l};代码中用到的队列运算的函数原型如表 4-1 所述,队列类型名为 QUEUE。
表 4-1 实现队列运算的函数原型及说明
【代码】int BFSTraverse(Graph G){//图 G 进行广度优先遍历,图采用邻接矩阵存储unsigned char*visited; //visited[]用于存储图 G 中各顶点的访问标 志,0 表示未访问int v,w;u;
QUEUEQ Q;∥申请存储顶点访问标志的空间,成功时将所申请空间初始化为 0 visited=(char*)calloc(G.vexnum, sizeof(char));If( (1) ) retum ERROR; (2) ; //初始化 Q 为空队列 for( v=0; v
参考解析
解析:1、visited==NULL
2、InitQueue(&Q)
3、EnQueue(&Q,v)
4、DeQueue(&Q,&u)
5、visited==0
2、InitQueue(&Q)
3、EnQueue(&Q,v)
4、DeQueue(&Q,&u)
5、visited==0
相关考题:
● 邻接矩阵和邻接表是图(网)的两种基本存储结构,对于具有 n个顶点、e条边的图, (59) 。(59)A. 进行深度优先遍历运算所消耗的时间与采用哪一种存储结构无关B. 进行广度优先遍历运算所消耗的时间与采用哪一种存储结构无关C. 采用邻接表表示图时,查找所有顶点的邻接顶点的时间复杂度为O(n*e)D. 采用邻接矩阵表示图时,查找所有顶点的邻接顶点的时间复杂度为O(n2)
广度优先遍历的含义是:从图中某个顶点v出发,在访问了v之后依次访问v的各个未被访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,且“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直至图中所有已被访问的顶点的邻接点都被访问到。(38)是下图的广度优先遍历序列。A.1 2 6 34 5B.1 2 34 5 6C.1 6 5 2 34D.1 64 52 3
阅读下列函数说明和C函数,将应填入(n)处的字句写在对应栏内。[说明]邻接表是图的一种顺序存储与链式存储结合的存储方法。其思想是:对于图G中的每个顶点 vi,将所有邻接于vi的顶点vj连成一个单链表,这个单链表就称为顶点vi的邻接表,其中表头称作顶点表结点VertexNode,其余结点称作边表结点EdgeNode。将所有的顶点表结点放到数组中,就构成了图的邻接表AdjList。邻接表表示的形式描述如下: define MaxVerNum 100 /*最大顶点数为100*/typedef struct node{ /*边表结点*/int adjvex; /*邻接点域*/struct node *next; /*指向下一个边表结点的指针域*/ }EdgeNode;typedef struct vnode{ /*顶点表结点*/int vertex; /*顶点域*/EdgeNode *firstedge; /*边表头指针*/}VertexNode;typedef VertexNode AdjList[MaxVerNum]; /*AdjList是邻接表类型*/typedef struct{AdjList adjlist; /*邻接表*/int n; /*顶点数*/}ALGraph; /*ALGraph是以邻接表方式存储的图类型*/深度优先搜索遍历类似于树的先根遍历,是树的先根遍历的推广。下面的函数利用递归算法,对以邻接表形式存储的图进行深度优先搜索:设初始状态是图中所有顶点未曾被访问,算法从某顶点v出发,访问此顶点,然后依次从v的邻接点出发进行搜索,直至所有与v相连的顶点都被访问;若图中尚有顶点未被访问,则选取这样的一个点作起始点,重复上述过程,直至对图的搜索完成。程序中的整型数组visited[]的作用是标记顶点i是否已被访问。[函数]void DFSTraverseAL(ALGraph *G)/*深度优先搜索以邻接表存储的图G*/{ int i;for(i=0;i<(1);i++) visited[i]=0;for(i=0;i<(1);i++)if((2)) DFSAL(G,i);}void DFSAL(ALGraph *G,int i) /*从Vi出发对邻接表存储的图G进行搜索*/{ EdgeNode *p;(3);p=(4);while(p!=NULL) /*依次搜索Vi的邻接点Vj*/{ if(! visited[(5)]) DFSAL(G,(5));p=p->next; /*找Vi的下一个邻接点*/}}
阅读下列算法说明和算法,将应填入(n)处的语句写在对应栏内。1. 【说明】实现连通图G的深度优先遍历(从顶点v出发)的非递归过程。【算法】第一步:首先访问连通图G的指定起始顶点v;第二步:从V出发,访问一个与v(1)p,再从顶点P出发,访问与p(2)顶点q,然后从q出发,重复上述过程,直到找不到存在(3)的邻接顶点为止。第三步:回退到尚有(4)顶点,从该顶点出发,重复第二、三步,直到所有被访问过的顶点的邻接点都已被访问为止。因此,在这个算法中应设一个栈保存被(5)的顶点,以便回溯查找被访问过顶点的未被访问过的邻接点。
● 对连通图进行遍历前设置所有顶点的访问标志为 false(未被访问) ,遍历图后得到一个遍历序列,初始状态为空。深度优先遍历的含义是:从图中某个未被访问的顶点 v 出发开始遍历,先访问 v 并设置其访问标志为 true(已访问) ,同时将 v 加入遍历序列,再从 v 的未被访问的邻接顶点中选一个顶点,进行深度优先遍历;若 v的所有邻接点都已访问,则回到 v 在遍历序列的直接前驱顶点,再进行深度优先遍历,直至图中所有顶点被访问过。 (40) 是下图的深度优先遍历序列。(40)A. 1 2 3 4 6 5B. 1 2 6 3 4 5C. 1 6 2 5 4 3D. 1 2 3 4 5 6
对于连通无向图G,以下叙述中,错误的是( )。A. G 中任意两个顶点之间存在路径 B. G 中任意两个顶点之间都有边 C. 从 G 中任意顶点出发可遍历图中所有顶点 D. G的邻接矩阵是对称的
以下关于图的遍历的叙述中,正确的是(61)。A.图的遍历是从给定的源点出发对每一个顶点仅访问一次的过程B.图的深度优先遍历方法不适用于无向图C.使用队列对图进行广度优先遍历D.图中有回路时则无法进行遍历
阅读以下说明和代码,填补代码中的空缺,将解答填入答题纸的对应栏内。 【说明】 图是很多领域中的数据模型,遍历是图的一种基本运算。从图中某顶点v出发进行广度优先遍历的过程是: ①访问顶点v; ②访问V的所有未被访问的邻接顶点W1 ,W2 ,..,Wk; ③依次从这些邻接顶点W1 ,W2 ,..,Wk出发,访问其所有未被访问的邻接顶点;依此类推,直到图中所有访问过的顶点的邻接顶点都得到访问。 显然,上述过程可以访问到从顶点V出发且有路径可达的所有顶点。对于从v出发不可达的顶点u,可从顶点u出发再次重复以上过程,直到图中所有顶点都被访问到。 例如,对于图4-1所示的有向图G,从a出发进行广度优先遍历,访问顶点的一种顺序为a、b、c、e、f、d。设图G采用数组表示法(即用邻接矩阵arcs存储),元素arcs[i][j]定义如下:图4-1的邻接矩阵如图4-2所示,顶点a~f对应的编号依次为0~5.因此,访问顶点a的邻接顶点的顺序为b,c,e。 函数BFSTraverse(Graph G)利用队列实现图G的广度优先遍历。 相关的符号和类型定义如下: define MaxN 50 /*图中最多顶点数*/ typedef int AdjMatrix[MaxN][MaxN]; typedef struct{ int vexnum, edgenum; /*图中实际顶点数和边(弧)数*/ AdjMatrix arcs; /*邻接矩阵*/ )Graph; typedef int QElemType; enum {ERROR=0;OK=1}; 代码中用到的队列运算的函数原型如表4-1所述,队列类型名为QUEUE。 表4-1 实现队列运算的函数原型及说明【代码】 int BFSTraverse(Graph G) {//对图G进行广度优先遍历,图采用邻接矩阵存储 unsigned char*visited; //visited[]用于存储图G中各顶点的访问标志,0表示未访问 int v, w, u; QUEUEQ Q; ∥申请存储顶点访问标志的空间,成功时将所申请空间初始化为0 visited=(char*)calloc(G.vexnum, sizeof(char)); If( (1) ) retum ERROR; (2) ; //初始化Q为空队列 for( v=0; vG.vexnum; v++){ if(!visited[v]){ //从顶点v出发进行广度优先遍历 printf(%d,v); //访问顶点v并将其加入队列 visited[v]=1; (3) ; while(!isEmpty(Q)){ (4) ; //出队列并用u表示出队的元素 for(w=0;vG.vexnum; w++){ if(G.arcs[u][w]!=0 (5) ){ //w是u的邻接顶点且未访问过 printf(%d, w); //访问顶点w visited[w]=1; EnQueue(Q, w); } } } } free(visited); return OK; )//BFSTraverse
阅读下列说明和C代码,回答问题1至问题2,将解答写在答题纸的对应栏内。【说明】一个无向连通图G点上的哈密尔顿(Hamiltion)回路是指从图G上的某个顶点出发,经过图上所有其他顶点一次且仅一次,最后回到该顶点的路径。哈密尔顿回路算法的基础如下:假设图G存在一个从顶点V0出发的哈密尔顿回路V1--V2--V3--...--Vn-1--V0。算法从顶点V0出发,访问该顶点的一个未被访问的邻接顶点V1,接着从顶点V1出发,访问V1一个未被访问的邻接顶点V2,..。;对顶点Vi,重复进行以下操作:访问Vi的一个未被访问的邻接接点Vi+1;若Vi的所有邻接顶点均已被访问,则返回到顶点Vi-1,考虑Vi-1的下一个未被访问的邻接顶点,仍记为Vi;直到找到一条哈密尔顿回路或者找不到哈密尔顿回路,算法结束。【C代码】下面是算法的C语言实现。(1)常量和变量说明n :图G中的顶点数c[][]:图G的邻接矩阵K:统计变量,当前已经访问的顶点数为k+1x[k]:第k个访问的顶点编号,从0开始Visited[x[k]]:第k个顶点的访问标志,0表示未访问,1表示已访问(2)C程序#include #include #define MAX 100voidHamilton(intn,int x[MAX,intc[MAX][MAX]){int;int visited[MAX];int k;/*初始化 x 数组和 visited 数组*/for (i=0:i=0){x[k]=x[k]+1;while(x[k]【问题1】(10分)根据题干说明。填充C代码中的空(1)~(5)。【问题2】(5分)根据题干说明和C代码,算法采用的设计策略为( ),该方法在遍历图的顶点时,采用的是( )方法(深度优先或广度优先)。
下面关于图的遍历说法不正确的是()。A.遍历图的过程实质上是对每个顶点查找其邻接点的过程B.深度优先搜索和广度优先搜索对无向图和有向图都适用C.深度优先搜索和广度优先搜索对顶点访问的顺序不同,它们的时间复杂度也不相同D.深度优先搜索是一个递归的过程,广度优先搜索的过程中需附设队列
对于具有n个顶点、6条边的图()。A.采用邻接矩阵表示图时,查找所有顶点的邻接顶点的时间复杂度为O(n2)B.进行广度优先遍历运算所消耗的时间与采用哪一种存储结构无关C.采用邻接表表示图时,查找所有顶点的邻接顶点的时间复杂度为O(n*e)D.进行深度优先遍历运算所消耗的时间与采用哪一种存储结构无关
阅读下列说明和?C?代码,回答问题?1?至问题?2,将解答写在答题纸的对应栏内。【说明】一个无向连通图?G?点上的哈密尔顿(Hamiltion)回路是指从图?G?上的某个顶点出发,经过图上所有其他顶点一次且仅一次,最后回到该顶点的路劲。一种求解无向图上哈密尔顿回路算法的基础私下如下:假设图?G?存在一个从顶点?V0?出发的哈密尔顿回路?V1——V2——V3——...——Vn-1——V0。算法从顶点?V0?出发,访问该顶点的一个未被访问的邻接顶点?V1,接着从顶点?V1?出发,访问?V1?一个未被访问的邻接顶点?V2,..。;对顶点?Vi,重复进行以下操作:访问?Vi?的一个未被访问的邻接接点?Vi+1;若?Vi?的所有邻接顶点均已被访问,则返回到顶点?Vi-1,考虑Vi-1?的下一个未被访问的邻接顶点,仍记为?Vi;知道找到一条哈密尔顿回路或者找不到哈密尔顿回路,算法结束。【C?代码】下面是算法的?C?语言实现。(1)常量和变量说明n :图?G?中的顶点数c[][]:图?G?的邻接矩阵K:统计变量,当期已经访问的定点数为?k+1x[k]:第?k?个访问的顶点编号,从?0?开始Visited[x[k]]:第?k?个顶点的访问标志,0?表示未访问,1?表示已访问⑵C?程序【问题?1】(10?分)根据题干说明。填充?C?代码中的空(1)~(5)。【问题?2】(5?分)根据题干说明和?C?代码,算法采用的设计策略为( ),该方法在遍历图的顶点时,采用的是(?)方法(深度优先或广度优先)。
下列关于图遍历的说法不正确的是()。A、连通图的深度优先搜索是一个递归过程B、图的广度优先搜索中邻接点的寻找具有“先进先出”的特征C、非连通图不能用深度优先搜索法D、图的遍历要求每一顶点仅被访问一次
下列有关图遍历的说法中不正确的是()A、连通图的深度优先搜索是一个递归过程B、图的广度优先搜索中邻接点的寻找具有“先进先出”的特征C、非连通图不能用深度优先搜索法D、图的遍历要求每一顶点仅被访问一次
多选题以下说法中正确的是A连通图的广度优先搜索中一般要采用队列来暂存刚访问过的顶点B图的深度优先搜索中一般要采用栈来暂存刚访问过的顶点C有向图的遍历不可采用广度优先搜索方法D无向图中的极大连通子图称为连通分量
单选题下列关于图遍历的说法不正确的是()。A连通图的深度优先搜索是一个递归过程B图的广度优先搜索中邻接点的寻找具有“先进先出”的特征C非连通图不能用深度优先搜索法D图的遍历要求每一顶点仅被访问一次