阅读下列说明和流程图,将应填入(n)处。[流程图说明]流程图1-1描述了一个算法,该算法将给定的原字符串中的所有前导空白和尾部空白都删除,但保留非空字符之间的空白。例如,原字符串“ File Name ”,处理后变成“File Name”。流程图1-2、流程图1-3、流程图1-4分别详细描述了流程图1-1中的框A,B,C。假设原字符串中的各个字符依次存放在字符数组ch的各元素ch(1),ch(2),…,ch(n)中,字符常量KB表示空白字符。流程图1-1的处理过程是:先从头开始找出该字符串中的第一个非空白字符ch(i),再从串尾开始向前找出位于最末位的非空白字符ch(j),然后将ch(i),…,ch(j)依次送入 ch(1),ch(2),…中。如果原字符串中没有字符或全是空白字符,则输出相应的说明。在流程图中,strlen是取字符串长度函数。[问题]在流程图1-1中,判断框P中的条件可表示为:i>(5)
阅读下列说明和流程图,将应填入(n)处。
[流程图说明]
流程图1-1描述了一个算法,该算法将给定的原字符串中的所有前导空白和尾部空白都删除,但保留非空字符之间的空白。例如,原字符串“ File Name ”,处理后变成“File Name”。流程图1-2、流程图1-3、流程图1-4分别详细描述了流程图1-1中的框A,B,C。
假设原字符串中的各个字符依次存放在字符数组ch的各元素ch(1),ch(2),…,ch(n)中,字符常量KB表示空白字符。
流程图1-1的处理过程是:先从头开始找出该字符串中的第一个非空白字符ch(i),再从串尾开始向前找出位于最末位的非空白字符ch(j),然后将ch(i),…,ch(j)依次送入 ch(1),ch(2),…中。如果原字符串中没有字符或全是空白字符,则输出相应的说明。在流程图中,strlen是取字符串长度函数。
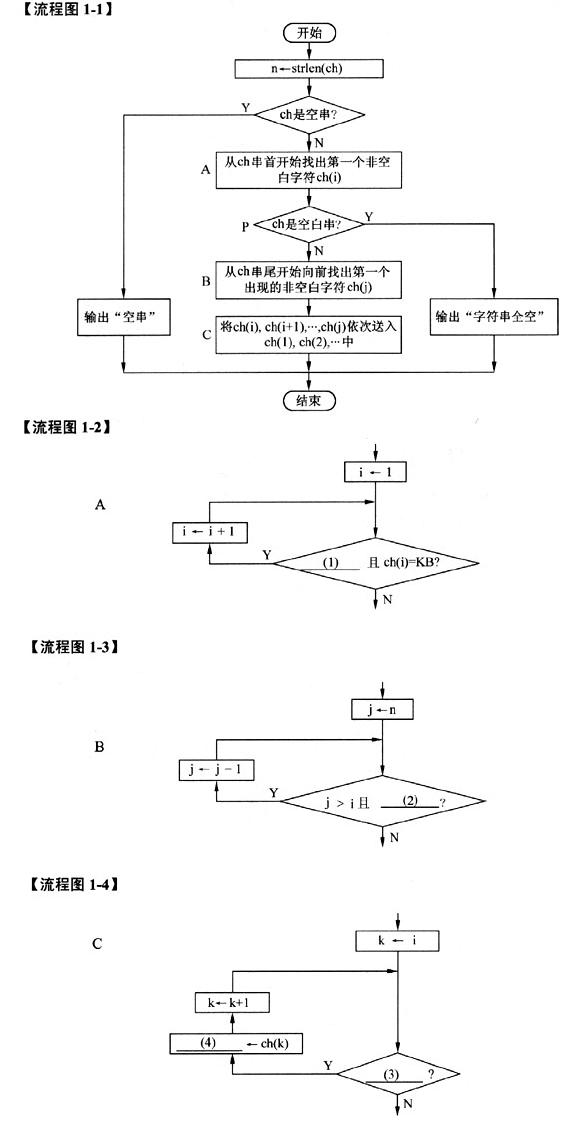
[问题]在流程图1-1中,判断框P中的条件可表示为:
i>(5)
相关考题:
阅读以下技术说明和流程图,根据要求回答问题1至问题3。[说明]图4-8的流程图所描述的算法功能是将给定的原字符串中的所有前部空白和尾部空白都删除,但保留非空字符。例如,原字符串“ FileName ”,处理变成“File Name”。图4-9、图4-10和图4-11分别详细描述了图4-8流程图中的处理框A、B、C。假设原字符串中的各个字符依次存放在字符数组ch的各元素ch(1)、ch(2)、…、ch(n)中,字符常量 KB表示空白字符。图4-8所示的流程图的处理过程是:先从头开始找出该字符串中的第一个非空白字符ch(i),再从串尾开始向前找出位于最末位的非空白字符ch(j),然后将ch(i)、……、ch(j)依次送入ch(1)、ch(2)、……中。如果字符串中没有字符或全是空白字符,则输出相应的说明。在图4-8流程图中,strlen()是取字符串长度函数。请将图4-9、图4-10和图4-11流程图中(1)~(4)空缺处的内容填写完整。
阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入对应栏内。[说明]下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中,n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i为字符串A中当前正在进行比较的动态予串首字符的下标,j为字符串B的下标,k为指定关键词出现的次数。[流程图]
阅读以下说明和流程图,回答问题1-2,将解答填入对应的解答栏内。[说明]下面的流程图采用欧几里得算法,实现了计算两正整数最大公约数的功能。给定正整数m和 n,假定m大于等于n,算法的主要步骤为:(1)以n除m并令r为所得的余数;(2)若r等于0,算法结束;n即为所求;(3)将n和r分别赋给m和n,返回步骤(1)。[流程图][问题1] 将流程图中的(1)~(4)处补充完整。[问题2] 若输入的m和n分别为27和21,则A中循环体被执行的次数是(5)。
阅读以下说明和流程图,将应填入(n)处的字句写在对应栏内。[说明]下面的流程图用于计算一个英文句子中最长单词的长度(即单词中字母个数)MAX。假设该英文句子中只含字母、空格和句点“.”,其中句点表示结尾,空格之间连续的字母串称为单词。[流程图]
试题一(共15 分 )阅读以下说明和流程图,将应填入 (n) 处的字句写在答题纸的对应栏内。【 说明 】下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中nm≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i 为字符串 A 中当前正在进行比较的动态子串首字符的下标,j为字符串B 的下标,k为指定关键词出现的次数。
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。[说明]下面流程图的功能是:在给定的两个字符串中查找最长的公共子串,输出该公共子串的长度L及其在各字符串中的起始位置(L=0时不存在公共字串)。例如,字符串"The light is not bright tonight"与"Tonight the light is not bright"的最长公共子串为"he light is not bright",长度为22,起始位置分别为2和10。设A[1:M]表示由M个字符A[1],A[2],…,A[M]依次组成的字符串;B[1:N]表示由N个字符B[1],B[2],…,B[N]依次组成的字符串,M≥N≥1。本流程图采用的算法是:从最大可能的公共子串长度值开始逐步递减,在A、B字符串中查找是否存在长度为L的公共子串,即在A、B字符串中分别顺序取出长度为L的子串后,调用过程判断两个长度为L的指定字符串是否完全相同(该过程的流程略)。[流程图]
阅读以下说明和流程图,将应填入(n)处的字句写在答题纸的对应栏内。【说明】 下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在"aaaa"中只出现两次"aa"。该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i 为字符串 A 中当前正在进行比较的动态子串首字符的下标,j为字符串B的下标,k为指定关键词出现的次数。【流程图】