试题四(共 15 分)阅读以下说明和 C 语言函数,将应填入 (n) 处的字句写在答题纸的对应栏内。[说明]已知包含头结点(不存储元素)的单链表的元素已经按照非递减方式排序,函数compress(NODE *head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。处理过程中,当元素重复出现时,保留元素第一次出现所在的结点。图4-1(a)、(b)是经函数 compress()处理前后的链表结构示例图。链表的结点类型定义如下:typedef struct Node {int data;struct Node *next;}NODE;[C 语言函数]void compress(NODE *head){ NODE *ptr,*q;ptr = (1) ; /* 取得第一个元素结点的指针 */while ( (2) ptr - next) {q = ptr - next;while(q (3) ) { /* 处理重复元素 */(4) = q - next;free(q);q = ptr - next;}(5) = ptr - next;}/* end of while */}/* end of compress */
试题四(共 15 分)
阅读以下说明和 C 语言函数,将应填入 (n) 处的字句写在答题纸的对应栏内。
[说明]
已知包含头结点(不存储元素)的单链表的元素已经按照非递减方式排序,函数compress(NODE *head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
处理过程中,当元素重复出现时,保留元素第一次出现所在的结点。
图4-1(a)、(b)是经函数 compress()处理前后的链表结构示例图。
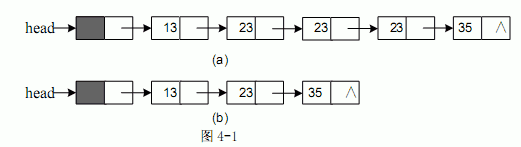
链表的结点类型定义如下:
typedef struct Node {
int data;
struct Node *next;
}NODE;
[C 语言函数]
void compress(NODE *head)
{ NODE *ptr,*q;
ptr = (1) ; /* 取得第一个元素结点的指针 */
while ( (2) && ptr -> next) {
q = ptr -> next;
while(q && (3) ) { /* 处理重复元素 */
(4) = q -> next;
free(q);
q = ptr -> next;
}
(5) = ptr -> next;
}/* end of while */
}/* end of compress */
相关考题:
●试题四阅读下列函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。【说明】函数QuickSort是在一维数组A[n]上进行快速排序的递归算法。【函数】void QuickSort(int A[],int s,int t){int i=s,j=t+1,temp;int x=A[s];do{do i++;while (1) ;do j--;while(A[j]x);if(ij){temp=A[i]; (2) ; (3) ;}}while(ij);A[a]=A[j];A[j]=x;if(si-1) (4) ;if(j+1t) (5) ;}
●试题一阅读下列函数说明和C代码,把应填入其中n处的字句写在答卷的对应栏内。【函数1.1说明】函数strcpy(char*to,char*from)将字符串from复制到字符串to。【函数1.1】void strcpy(char*to,char*from){while( ( 1 ) );}【函数1.2说明】函数merge(int a[ ],int n,int b[ ],int m,int *c)是将两个从小到大有序数组a和b复制合并出一个有序整数序列c,其中形参n和m分别是数组a和b的元素个数。【函数1.2】void merge(int a[ ],int n,int b[ ],int m,int *c){ int i,j;for(i=j=0;i<n j<m;)*c++=a[i]<b[j]? a[i++]:b[j++];while( (2) )*c++=a[i++];while( (3) )*c++=b[j++];}【函数1.3说明】递归函数sum(int a[ ],int n)的返回值是数组a[ ]的前n个元素之和。【函数1.3】int sum(int a[ ],int n){ if(n>0)return (4) ;else (5) ;}
●试题三阅读下列函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。【说明】函数diff的功能是:根据两个由整数(都大于-32768)按升序构成的单链表L1和L2(分别由A,B指向)构造一个单链表L3(由*r指向),要求L3中的所有整数都是L1,并且不是L2中的整数,还要求L3中的所有整数都两两不等。【函数】#include<malloC.htypedef struct node{int d;struct node *next}Node;void diff(Node *A,Node *B,Node **r){int lastnum;Node*p;*r=NULL;if(!A)return;while( (1) )if(A-dB-d){lastnum=A-d;p=(Node*)malloc(sizeof(Node));p-d=lastnum;p-next=*r; (2) ;doA=A-next;while( (3) );}else if(A-dB-d)B=B-next;else{(4) ;lastnum=A-d;while (A A-d==lastnum)A=A-next;}while(A){lastnum=A-d;p=(Node*)malloc(sizeof(Node));p-d=lastnum;(5) ;*r=p;while (A A-d==lastnum) A=A-next;}}
●试题二阅读下列函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。【说明2.1】L为一个带头结点的循环链表。函数deletenode(LinkList L,int c)的功能是删除L中数据域data的值大于c的所有结点,并由这些结点组建成一个新的带头结点的循环链表,其头指针作为函数的返回值。【函数2.1】LinkList deletenode(LinkList L,int c){LinkList Lc,p,pre;pre=L;p= (1) ;Lc=(LinkList)malloc(sizeof(ListNode));Lc-next=Lc;while(p!=L)if(p-datac){(2) ;(3) ;Lc-next=p;p=pre-next;}else{pre=p;p=pre-next;}return Lc;}【说明2.2】递归函数dec_to_k_2(int n,int k)的功能是将十进制正整数n转换成k(2≤k≤9)进制数,并打印。【函数2.2】dec_to_k_2(int n,int k){∥将十进制正整数n转换成k(2≤k≤9)进制数if(n!=0){dec_to_k_2( (4) ,k);printf("%d", (5) );}}
●试题三阅读下列函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。【说明3.1】假设以带头结点的单循环链表作非递减有序线性表的存储结构。函数deleteklist(LinkList head)的功能是删除表中所有数值相同的多余元素,并释放结点空间。例如:链表初始元素为:(7,10,10,21,30,42,42,42,51,70)经算法操作后变为:(7,10,21,30,42,51,70)【函数3.1】void deleteklist(LinkList head){LinkNode*p,*q;p=head-next;while(p!=head){q=p-next;while( (1) ){(2) ;free(q);q=p-next;}p=p-next;}}【说明3.2】已知一棵完全二叉树存放于一个一维数组T[n]中,T[n]中存放的是各结点的值。下面的程序的功能是:从T[0]开始顺序读出各结点的值,建立该二叉树的二叉链表表示。【函数3.2】#includeistream.htypedef struct node {int data;stuct node leftChild,rightchild;}BintreeNode;typedef BintreeNode*BinaryTree;void ConstrncTree(int T[],int n,int i,BintreeNode*&ptr){if(i=n) (3) ;∥置根指针为空else{ptr=-(BTNode*)malloc(sizeof(BTNode))ptr-data=T[i];ConstrucTree(T,n,2*i+1, (4) );ConstrucTree(T,n, (5) ,ptr-rightchild);}}main(void){/*根据顺序存储结构建立二叉链表*/Binarytree bitree;int n;printf("please enter the number of node:\n%s";n);int*A=(int*)malloc(n*sizeof(int));for(int i=0;i<n;i++)scanf("%d,A+i);/*从键盘输入结点值*/for(int i=0;i<n;i++)printf("%d",A[i]);ConstructTree(A,n,0,bitree);}
●试题三阅读下列函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。【说明】函数move(int*a,int n)用于整理数组a[]的前n个元素,使其中小于0的元素移到数组的前端,大于0的元素移到数组的后端,等于0的元素留在数表中间。令a[0]~a[low-1]小于0(初始为空);a[low]~a[i-1]等于0(初始为空);a[i]~a[high]还未考察,当前考察元素为a[i]。a[high+1]~a[n-1]大于0(初始为空)。【函数】move(int*a,int n){int i,low,high,t;low=i=0;high=n-1;while( (1) )if(a[i]0){t=a[i];a[i]=a[low];a[low]=t;(2) ;i++;}else if( (3) ){t=a[i];a[i]=a[high];a[high]=t;(4) ;}else (5) ;}
阅读以下说明和流程图,将应填入(n)处的字句写在对应栏内。【说明】已知头指针分别为La和lb的有序单链表,其数据元素都是按值非递减排列。现要归并La和Lb得到单链表Lc,使得Lc中的元素按值非递减排列。程序流程图如下所示:
阅读以下说明和C语言函数,将应填入(n)处的字句写在对应栏内。[说明]完成以下中序线索化二叉树的算法。[函数]Typedef int datatype;Typedef struct node {Int ltag, rtag;Datatype data;*lchild,* rchild;}bithptr;bithptr pre;void inthread ( p );{if{inthread ( p->lchild );if ( p->lchild==unll ) (1);if ( P->RCHILD=NULL) p->rtag=1;if (2){if (3) pre->rchild=p;if ( p->1tag==1 )(4);}INTHREAD ( P->RCHILD );(5);}}
阅读以下函数说明和C语言函数,将应填入(n)处的字句写在对应栏内。[说明1]L为一个带头结点的循环链表。函数LinkList deletenode(LinkList L,int c)的功能是删除L中数据域data的值大于C的所有结点,并由这些结点组建成一个新的带头结点的循环链表,其头指针作为函数的返回值。[C函数1]LinkList deletenode(LinkList L,int c){LinkList Lc,P,pre;pre=L;p=(1);Lc=(LinkList)malloc(sizeof(Listnode));Lc->next=Lc;while(P!=L)if(p->data>C){(2);(3);Lc->next=p;p=pre->next;}else{pre=p;p=pre->next;}return Lc;}[说明2]递归函数dec_to_k_2(int n,int k)的功能是将十进制正整数n转换成k(2≤k≤9)进制数,并打印。[C函数2]dec to k 2(int n,int k){ if(n!=O){dec to k 2( (4) ,k);printf("%d", (5) );}}
阅读下列说明和C函数,将应填入(n)处的字句写在对应栏内。【说明】已知集合A和B的元素分别用不含头结点的单链表存储,函数Difference()用于求解集合A与B的差集,并将结果保存在集合A的单链表中。例如,若集合A={5,10, 20,15,25,30},集合B={5,15,35,25},如图(a)所示,运算完成后的结果如图(b)所示。链表结点的结构类型定义如下:typedef struct Node{ElemType elem;struct Node *next;}NodeType;【C函数】void Difference(NodeType **LA,NodeType *LB){NodeType *pa, *pb, *pre, *q;pre=NULL;(1);while (pa) {pb=LB;while((2))pb=pb->next;if((3)) {if(!pre)*LA=(4);else(5)=pa->next;q = pa;pa=pa->next;free(q);}else {(6);pa=pa->next;}}}
阅读以下说明和C语言函数,将应填入(n)处的字句写在对应栏内。【说明】函数sort (NODE *head)的功能是;用冒泡排序法对单链表中的元素进行非递减排序。对于两个相邻结点中的元素,若较小的元素在前面,则交换这两个结点中的元素值。其中,head指向链表的头结点。排序时,为了避免每趟都扫描到链表的尾结点,设置一个指针endptr,使其指向下趟扫描需要到达的最后一个结点。例如,对于图4-1(a)的链表进行一趟冒泡排序后,得到图4-1(b)所示的链表。链表的结点类型定义如下:typedef struct Node {int data;struct Node *next;} NODE;【C语言函数】void sort (NODE *head){ NODE *ptr,*preptr, *endptr;int tempdata;ptr = head -> next;while ((1)) /*查找表尾结点*/ptr = ptr -> next;endptr = ptr; /*令endptr指向表尾结点*/ptr =(2);while(ptr != endptr) {while((3)) {if (ptr->data > ptr->next->data){tempdata = ptr->data; /*交换相邻结点的数据*/ptr->data = ptr->next->data;ptr->next->data = tempdata;}preptr =(4); ptr = ptr -> next;}endptr =(5); ptr = head->next;}}
阅读以下函数说明和C语言函数,将应填入(n)处的字句写在答题纸的对应栏内。【函数2.1说明】递归函数sum(int a[], int n)的返回值是数组a[]的前n个元素之和。【函数2.1】int sum (int a[],int n){if(n>0) return (1);else (2);}【函数2.2说明】有3个整数,设计函数compare(int a,int b,int c)求其中最大的数。【函数2.2】int compare (int a, int b, int c ){ int temp, max;(3) a:b;(4) temp:c;}【函数2.3说明】递归函数dec(int a[],int n)判断数组a[]的前n个元素是否是不递增的。不递增返回 1,否则返回0。【函数2.3】int dec( int a[], int n ){if(n<=1) return 1;if(a[0]<a[1]) return 0;return (5);}
阅读以下说明和程序流程图,将应填入(n)处的字句写在对应栏内。[说明]当一元多项式中有许多系数为零时,可用一个单链表来存储,每个节点存储一个非零项的指受和对应系数。为了便于进行运算,用带头节点的单链表存储,头节点中存储多项式中的非零项数,且各节点按指数递减顺序存储。例如:多项式8x5-2x2+7的存储结构为:流程图图3-1用于将pC(Node结构体指针)节点按指数降序插入到多项式C(多项式POLY指针)中。流程图中使用的符号说明如下:(1)数据结构定义如下:define EPSI 1e-6struct Node{ /*多项式中的一项*/double c; /*系数*/int e; /*指数*/Struct Node *next;};typedef struct{ /*多项式头节点*/int n; /*多项式不为零的项数*/struct Node *head;}POLY;(2)Del(POLY *C,struct Node *p)函数,若p是空指针则删除头节点,否则删除p节点的后继。(3)fabs(double c)函数返回实数C的绝对值。[图3-1](1)
阅读以下说明和C语言函数,将应填入(n)。【说明】已知包含头结点(不存储元素)的单链表的元素已经按照非递减方式排序,函数 compress(NODE*head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。处理过程中,当元素重复出现时,保留元素第一次出现所在的结点。图2-1(a)、(b)是经函数compress()处理前后的链表结构示例图。链表的结点类型定义如下:typedef struct Node{int data;struct Node *next;}NODE;【C语言函数】void compress(NODE *head){ NODE *ptr,*q;ptr= (1); /*取得第一个元素结点的指针*/while( (2) ptr->next) {q=ptr->next;while(q(3)) { /*处理重复元素*/(4)q->next;free(q);q=ptr->next;}(5) ptr->next;}/*end of while */}/*end of compress*/
阅读以下函数说明和C语言函数,将应填入(n)处的字句写在对应栏内。[说明]已知r[1...n]是n个记录的递增有序表,用折半查找法查找关键字为k的记录。若查找失败,则输出“failure",函数返回值为0;否则输出“success”,函数返回值为该记录的序号值。[C函数]int binary search(struct recordtype r[],int n,keytype k){ intmid,low=1,hig=n;while(low<=hig){mid=(1);if(k<r[mid].key) (2);else if(k==r[mid].key){printf("succesS\n");(3);}else (4);}printf("failure\n");(5);}
阅读以下说明和C语言函数,将应填入(n)处的字句写在对应栏内。【说明】下面的程序构造一棵以二叉链表为存储结构的二叉树算法。【函数】BTCHINALR *createbt ( BTCHINALR *bt ){BTCHINALR *q;struct node1 *s [30];int j,i;char x;printf ( "i,x =" ); scanf ( "%d,%c",i,x );while (i!=0 x!='$'){ q = ( BTCHINALR* malloc ( sizeof ( BTCHINALR )); //生成一个结点(1);q->1child = NULL;q->rchild = NULL;(2);if((3);){j=i/2 //j为i的双亲结点if(i%2==0(4) //i为j的左孩子else(5) //i为j的右孩子}printf ( "i,x =" ); scanf ( "%d,%c",i,x ); }return s[1]}
[说明]已知包含头节点(不存储元素)的单链表的元素已经按照非递减方式排序,函数compress(NODE *head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。处理过程中,当元素重复出现时,保留元素第一次出现所在的节点。图8-29(a)、(b)是经函数compress( )处理前后的链表结构示例图。链表的节点类型定义如下:typedef struct Node {int data;struct Node *next;}NODE;[C语言函数]void compress(NODE *head){NODE *ptr, *q;ptr= (1) ; /*取得第一个元素节点的指针*/while( (2) ptr->next) {q=ptr ->next;while(q (3) ){/*处理重复元素*/(4) =q ->next;free(q);q=ptr->next;}(5) =ptr->next;} /*end of while*/} /*end of compress*/
阅读以下说明和 C 代码,填补代码中的空缺,将解答填入答题纸的对应栏内。 【说明】 函数 GetListElemPtr(LinkList L,int i)的功能是查找含头结点单链表的第i个元素。若找到,则返回指向该结点的指针,否则返回空指针。 函数DelListElem(LinkList L,int i,ElemType *e) 的功能是删除含头结点单链表的第 i个元素结点,若成功则返回 SUCCESS ,并由参数e 带回被删除元素的值,否则返回ERROR 。 例如,某含头结点单链表 L 如图 4-1 (a) 所示,删除第 3 个元素结点后的单链表如 图 4-1 (b) 所示。图4-1define SUCCESS 0 define ERROR -1 typedef int Status; typedef int ElemType; 链表的结点类型定义如下: typedef struct Node{ ElemType data; struct Node *next; }Node ,*LinkList; 【C 代码】 LinkList GetListElemPtr(LinkList L ,int i) { /* L是含头结点的单链表的头指针,在该单链表中查找第i个元素结点: 若找到,则返回该元素结点的指针,否则返回NULL */ LinkList p; int k; /*用于元素结点计数*/ if (i1 ∣∣ !L ∣∣ !L-next) return NULL; k = 1; P = L-next; / *令p指向第1个元素所在结点*/ while (p (1) ) { /*查找第i个元素所在结点*/ (2) ; ++k; } return p; } Status DelListElem(LinkList L ,int i ,ElemType *e) { /*在含头结点的单链表L中,删除第i个元素,并由e带回其值*/ LinkList p,q; /*令p指向第i个元素的前驱结点*/ if (i==1) (3) ; else p = GetListElemPtr(L ,i-1); if (!p ∣∣ !p-next) return ERROR; /*不存在第i个元素*/ q = (4) ; /*令q指向待删除的结点*/ p-next = q-next; /*从链表中删除结点*/ (5) ; /*通过参数e带回被删除结点的数据*/ free(q); return SUCCESS; }
阅读以下说明和 C 函数,填补代码中的空缺,将解答填入答题纸的对应栏内。 【说明】 函数 Combine(LinkList La,LinkList Lb)的功能是:将元素呈递减排列的两个含头结 点单链表合并为元素值呈递增(或非递减)方式排列的单链表,并返回合并所得单链表 的头指针。例如,元素递减排列的单链表 La 和 Lb 如图 4-1 所示,合并所得的单链表如图 4-2 所示。图 4-1 合并前的两个链表示意图图 4-2 合并后所得链表示意图设链表结点类型定义如下: typedef struct Node{ int data; struct Node *next; }Node ,*LinkList; 【C 函数】 LinkList Combine(LinkList La ,LinkList Lb) { //La 和 Lb 为含头结点且元素呈递减排列的单链表的头指针 //函数返回值是将 La 和 Lb 合并所得单链表的头指针 //且合并所得链表的元素值呈递增(或非递减)方式排列 (1) Lc ,tp ,pa ,pb;; //Lc 为结果链表的头指针 ,其他为临时指针 if (!La) return NULL; pa = La-next; //pa 指向 La 链表的第一个元素结点 if (!La) return NULL; pa = La-next; //pb 指向 Lb 链表的第一个元素结点 Lc = La; //取 La 链表的头结点为合并所得链表的头结点 Lc-next = NULL; while ( (2) ){ //pa 和 pb 所指结点均存在(即两个链表都没有到达表尾) //令tp指向 pa 和 pb 所指结点中的较大者 if (pa-data pb-data) { tp = pa; pa = pa-next; } else{ tp = pb; pb = pb-next; } (3) = Lc-next; //tp 所指结点插入 Lc 链表的头结点之后 Lc-next = (4) ; } tp = (pa)? pa : pb; //设置 tp 为剩余结点所形成链表的头指针 //将剩余的结点合并入结果链表中, pa 作为临时指针使用 while (tp) { pa = tp-next; tp-next = Lc-next; Lc-next = tp; (5) ; } return Lc; }
●试题二阅读下列函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。【说明】该程序运行后,输出下面的数字金字塔【程序】includestdio.hmain (){char max,next;int i;for(max=′1′;max=′9′;max++){for(i=1;i=20- (1) ;++i)printf(" ");for(next= (2) ;next= (3) ;next++)printf("%c",next);for(next= (4) ;next= (5) ;next--)printf("%c",next);printf("\n");}}
()阅读下列说明和C语言程序,将应填入 (n)处的语句写在答题纸的对应栏内。[说明]下面程序是一个带参数的主函数,其功能是显示在命令行中输入的文本文件内容。[C语言函数]#include"stdio.h"main(argc,argv) int argc; char *argv[]; { (1) ; if((fp=fopen(argv[1],”r’’))== (2) ) { printf(”file not open!\n”);exit(0);} while( (3) ) putchar( (4) ); (5); }
阅读以下说明和C语言函数,将解答填入答题纸的对应栏内。【说明】函数sort (NODE *head)的功能是:用冒泡排序法对单链表中的元素进行非递减排序。对于两个相邻结点中的元素,若较小的元素在前面,则交换这两个结点中的元素值。其中,head指向链表的头结点。排序时,为了避免每趟都扫描到链表的尾结点,设置一个指针endptr,使其指向下趟扫描需要到达的最后一个结点。例如,对于图(a)的链表进行一趟冒泡排序后,得到图(b)所示的链表。
阅读以下说明和C代码,填补代码中的空缺,将解答填入答题纸的对应栏内。[说明]函数GetListElemPtr(LinkList L,int i)的功能是查找含头结点单链表的第i个元素。若找到,则返回指向该结点的指针,否则返回空指针。函数DelListElem(LinkList L,int i,ElemType *e)的功能是删除含头结点单链表的第i个元素结点,若成功则返回SUCCESS,并由参数e带回被删除元素的值,否则返回ERROR。例如,某含头结点单链表L如下图(a)所示,删除第3个元素结点后的单链表如下图(b)所示。1.jpg#define SUCCESS 0 #define ERROR -1 typedef intStatus; typedef intElemType;链表的结点类型定义如下:typedef struct Node{ ElemType data; struct Node *next; }Node,*LinkList; [C代码] LinkListGetListElemPtr(LinkList L,int i) { /*L是含头结点的单链表的头指针,在该单链表中查找第i个元素结点; 若找到,则返回该元素结点的指针,否则返回NULL */ LinkList p; int k; /*用于元素结点计数*/ if(i<1 || !L || !L->next) return NULL; k=1; p=L->next; /*令p指向第1个元素所在结点*/ while(p ++k; } return p; } StatusDelListElem(LinkList L,int i,ElemType *e) { /*在含头结点的单链表L中,删除第i个元素,并由e带回其值*/ LinkList p,q; /*令P指向第i个元素的前驱结点*/ if(i==1) ______; else p=GetListElemPtr(L,i-1); if(!P || !p->next) return ERROR; /*不存在第i个元素*/ q=______; /*令q指向待删除的结点*/ p->next=q->next; //从链表中删除结点*/ ______; /*通过参数e带回被删除结点的数据*/ free(q); return SUCCESS; }
阅读以下说明和C函数,填补代码中的空缺,将解答填入答题纸的对应栏内。[说明]函数ReverseList(LinkList headptr)的功能是将含有头结点的单链表就地逆置。处理思路是将链表中的指针逆转,即将原链表看成由两部分组成:已经完成逆置的部分和未完成逆置的部分,令s指向未逆置部分的第一个结点,并将该结点插入已完成部分的表头(头结点之后),直到全部结点的指针域都修改完成为止。例如,某单链表如图1所示,逆置过程中指针s的变化情况如图2所示。链表结点类型定义如下:typedef struct Node{ int data; Struct Node *next; }Node,*LinkList; [C函数] void ReverseList(LinkList headptr) { //含头结点的单链表就地逆置,headptr为头指针 LinkList p,s; if(______) return; //空链表(仅有头结点)时无需处理 P=______; //令P指向第一个元素结点 if(!P->next) return; //链表中仅有一个元素结点时无需处理 s=p->next; //s指向第二个元素结点 ______ =NULL; //设置第一个元素结点的指针域为空 while(s){ p=s; //令p指向未处理链表的第一个结点 s= ______; p->next=headptr->next; //将p所指结点插入已完成部分的表头 headptr->next= ______; } }
阅读以下说明和C函数,填补代码中的空缺,将解答填入答题纸的对应栏内。[说明]函数Combine(LinkList La,LinkList Lb)的功能是:将元素呈递减排列的两个含头结点单链表合并为元素值呈递增(或非递减)方式排列的单链表,并返回合并所得单链表的头指针。例如,元素递减排列的单链表La和Lb如图1所示,合并所得的单链表如图2所示。设链表结点类型定义如下:typedef Struct Node{ int data; struct Node*next; }Node,*LinkList; [C函数] LinkListCombine(LinkList La,LinkList Lb) { //La和Lb为含头结点且元素呈递减排列的单链表的头指针 //函数返回值是将La和Lb合并所得单链表的头指针 //且合并所得链表的元素值呈递增(或非递减)方式排列 ______Lc,tp,pa,pb; //Lc为结果链表的头指针,其他为临时指针 if(!La)returnNULL; pa=La->next; //pa指向La链表的第一个元素结点 if(!Lb) returnNULL; pb=Lb->next; //pb指向Lb链表的第一个元素结点 Lc=La; //取La链表的头结点为合并所得链表的头结点 Lc->next=NULL; while(______) { //pa和pb所指结点均存在(即两个链表都没有到达表尾) //令tp指向pa和pb所指结点中的较大者 if(pa->data>pb->data){ tp=pa; pa=pa->next; } else{ tp=pb; pb=pb->next; } ______ =Lc->next; //tp所指结点插入Lc链表的头结点之后 Lc->next=______; } tp=(pa)?pa:pb; //设置tp为剩余结点所形成链表的头指针 //将剩余的结点合并入结果链表中,pa作为临时指针使用 while (tp) { pa=tp->next; tp->next=Lc->next; Lc->next=tp; ______; } return Lc; }
阅读下列说明和?C++代码,将应填入(n)处的字句写在答题纸的对应栏内。【说明】阅读下列说明和?Java代码,将应填入?(n)?处的字句写在答题纸的对应栏内。【说明】某快餐厅主要制作并出售儿童套餐,一般包括主餐(各类比萨)、饮料和玩具,其餐品种类可能不同,但其制作过程相同。前台服务员?(Waiter)?调度厨师制作套餐。现采用生成器?(Builder)?模式实现制作过程,得到如图?6-1?所示的类图。